
Vorwort
Mit diesem Blog-Artikel können wir euch leider natürlich keine Data Science Ausbildung anbieten, sondern wollen auf die Problematik der Verwendung der Anaconda Distribution aufmerksam machen und eine Alternative vorstellen, wie man sich die optimale Enticklungsumgebung schafft.
Hintergrund
Die Anaconda Distribution [1] und dereren Ableger für minimalere Basisinstallationen Miniconda [2] haben sich schon unter vielen Data Scientists beliebt gemacht! Sie bieten mit dem freien conda Paketmanager [3] [4] eine schnelle und einfache Möglichkeit, Pakete und deren Abhängigkeiten auf Projektebene (über sog. "environments") zu verwalten. Während conda über eine BSD-3 Lizenz frei zugänglich und verwendbar ist, sorgen aber die aktualisierten Nutzungsbedingungen [5] seit September 2020 für Schlagzeilen in der Community. Während diese Distributionen für die Lehre, Forschung und NGOs weiterhin frei verwendbar bleiben, verstößt man aber mit jeder anderen Verwendung gegen die Nutzungsbedingungen. Der einzige Ausweg dazu führt über eine kommerzielle Lizenz [6], dessen Umweg Einzelne und KMUs oft nicht gehen wollen.
Doch es gibt einen anderen Weg!
Von der Community für die Community
Während Anaconda Pakete über deren eigenen "main/defaults" Kanal anbietet, gibt es von der Community "conda-forge" [7] einen Community-Kanal, der mit der Zeit zu immer mehr Beliebtheit gelangte. Diese Pakete sind zugleich auch oft aktueller, da die Entwickler ihre Pakete frei vertreiben können, ohne sich zuerst durch den großen Abhängigkeitsdschungel von Anaconda durchwühlen zu müssen.
Des Weiteren sind Pakete über conda-forge in der Originalfassung erhältlich, während Anaconda diese Pakete oft patched (verändert), bevor diese in den main Kanal aufgenommen werden. Diese Patches belaufen sich zum Beispiel oft auf den Einbau der Intel MKL Library [8] (Math Kernel zur Verwendung mathematischer Operationen), der zwar einen kleinen Performanceschub auf Intel Prozessoren bringt, aber bis heute nicht frei einsehbar ist. Dies wirft natürlich Fragen zur Transparenz auf....
Die Lösung zu diesem Dilemma bietet aber nun die conda-forge Community mit deren Distribution Miniforge [9], die den freien conda Paketmanager [4] standardmäßig mit deren Community Kanal conda-forge [7] verpackt und somit alle Verbindungen zu Anaconda kappt. Miniforge bietet somit mehrere Vorteile:
Transparent und frei zugänglich
Keine untransparenten Paketveränderungen
Schnelle Verfügbarkeit aktueller Paketversionen
Kompatibilität über mehrere Prozessorarchitekturen (x86_64, aarch64, ppc64le, Apple Silicone, etc.)
Und zu guter Letzt: "Tschüss bad business practices!" Anaconda :)
Die optimale Data Science Entwicklungsumgebung
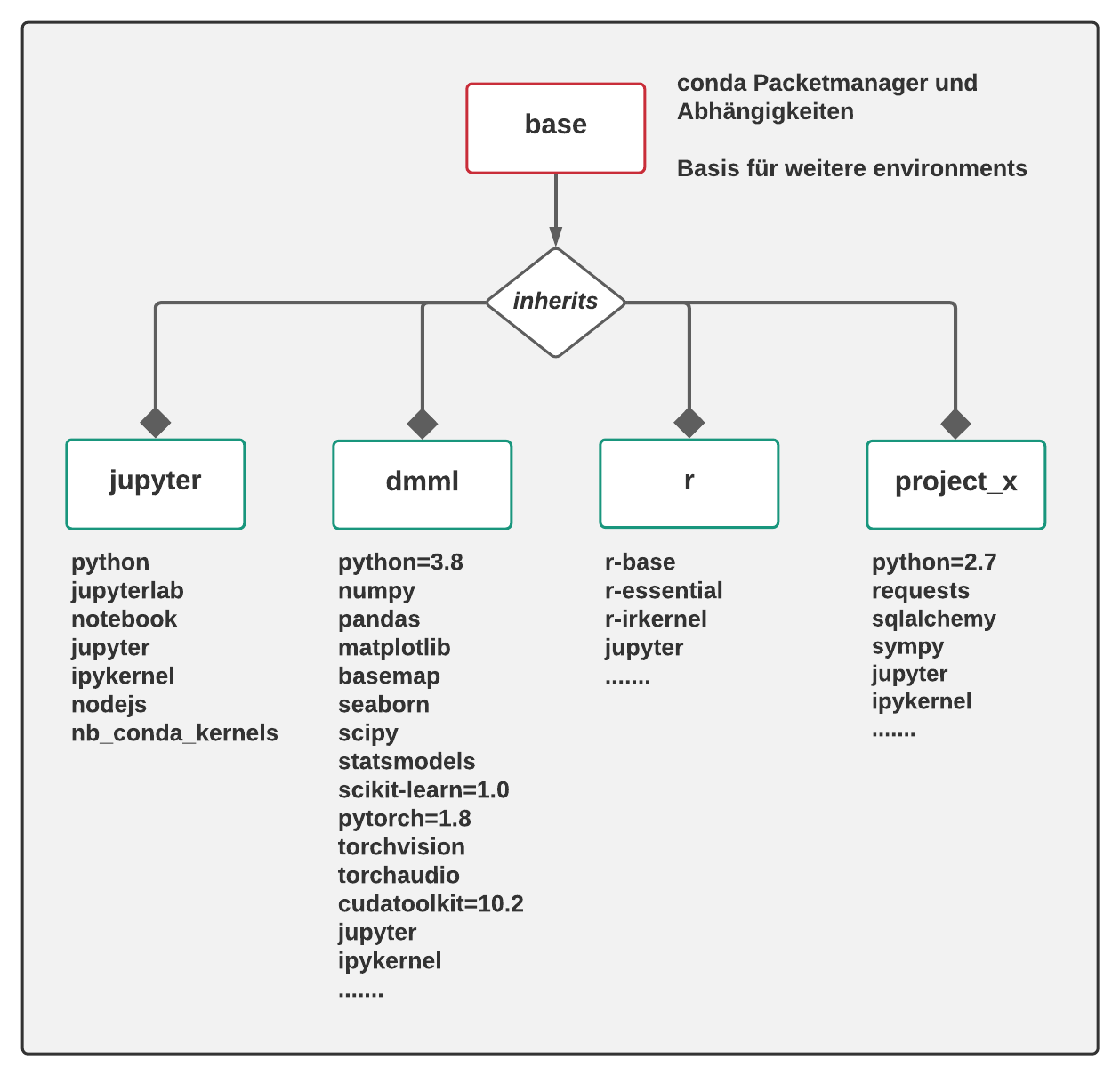
Beispiel-Setup: Environments mit installierten Paketen
(Quelle: Privat | Fabian Kovac)
Um uns nun selbst eine optimale Umgebung aufzusetzen, beginnen wir mit der Installation von Miniforge:
>> Download und Installationsanleitung
Nach der Installation öffnen wir unter Windows den "Conda Prompt" bzw. unter Linux/Mac das normale Terminal (conda sollte nach der Installation im Pfad ergänzt worden sein) und wir werden schon mit dem bereits vorinstallierten base Environment begrüßt!
Terminal mit Anzeige das aktiven Environments
(Quelle: Privat | Fabian Kovac)
Mit dem conda Paketmanager können wir nun Pakete und Environments verwalten. Online gibts dazu ein kleines Cheatsheet, das am Anfang mit den wichtigsten Befehlen als gutes Nachschlagewerk dient.
Diese Environments bieten dabei abgeschottete Umgebungen, um sich zum Beispiel pro Lehrveranstaltung oder Projekt alle benötigten Pakete und deren Abhängigkeiten in den jeweils benötigten Versionen zu installieren, ohne Installationen anderer Environments zu gefährden.
Im Rahmen dieses Tutorials erstellen wir nun zwei Environments, die auf keinem Data Science Rechner fehlen sollten!
Environment: jupyter
Jupyter Notebooks bzw. dessen Nachfolger Jupyterlab sind oft die Ausgangsbasis eines jeden Data Science Projekts. Diese Browserapplikation erlaubt es uns, über sogenannte Kernels in einem grafischen "Notizbuch" mit Programmiersprachen und deren Paketen zu interagieren (z.B. "ipykernel" für Python oder der "irkernel" für R). Diese Notizbücher bestehen aus zwei Arten von Blöcken:
Code-Blöcke: um Befehle in der jeweiligen Sprache abzusetzen, wobei unmittelbar darunter der Output angezeigt wird
Markdown-Blöcke: zur Dokumentation in Form von Markdown
Am Conda Prompt benötigen wir dazu folgende Befehle, um uns ein jupyter Environment einzurichten:
(base) $> conda create -n jupyter
(base) $> conda activate jupyter
(jupyter) $> conda install python jupyterlab notebook jupyter ipykernel nodejs nb_conda_kernelsDiese Befehle erzeugen uns a) ein Environment "jupyter", b) wechseln in das Environment und c) installieren die benötigten Pakete.
Der Star der Show ist dabei das Paket "nb_conda_kernels", mit dessen Hilfe automatisch alle Kernels aller anderen Environments über das jupyter Environment ansprechbar werden. Das erlaubt es dem jupyter Environment als Ausganspunkt für sämtliche Data Science Projekte über alle Environments hinweg zu dienen. Dies ist also unsere "Zentrale", mit der wir mit den Sprachen und Paketen anderer Environments interagieren.
Mit dem Befehl "jupyter-lab" starten wir nun unser Jupyterlab, auf das wir mit unserem Browser zugreifen können (Windows sollte den Browser automatisch öffnen, Linux/Mac benötigen die URL, die nach Ausführen des Befehls angezeigt wird). Auf Jupyterlab eingeloggt bekommen wir nun auch schon eine Übersicht über alle Environments mit den installierten Sprachen und Paketen, mit denen wir mit den oben genannten Notebooks loslegen können.
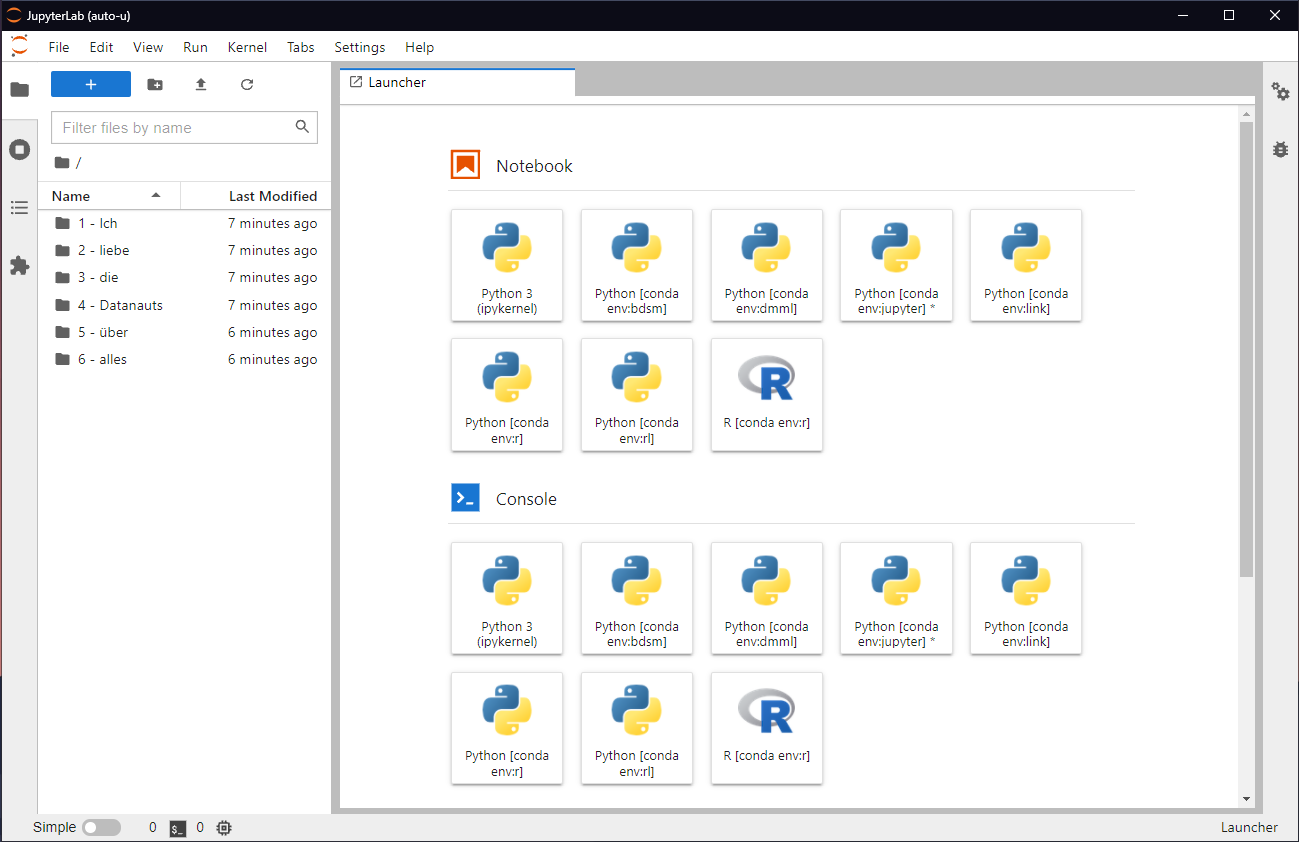
Jupyterlab mit installierten Environments
(Quelle: Privat | Fabian Kovac)
Um nun Environments im Jupyterlab angezeigt zu bekommen, benötigen wir natürlich weitere, wobei ein dmml Environment niemals fehlen sollte!
Environment: dmml
Ein Data Mining and Machine Learning (dmml) Environment sollte nicht im Werkzeugkasten fehlen. Die Pakete in diesem Environment erlauben es uns nicht nur die komplette Datenvorverarbeitung zu übernehmen, sondern auch Daten zu visualisieren sowie Modelle und neuronale Netze zu trainieren.
Am Conda Prompt benötigen wir dazu folgende Befehle, um uns ein dmml Environment einzurichten:
(jupyter) $> conda create -n dmml
(jupyter) $> conda activate dmml
(dmml) $> conda install python numpy pandas matplotlib basemap seaborn scipy statsmodels scikit-learn jupyter ipykernel
(dmml) $> conda install pytorch torchvision torchaudio cpuonly -c pytorchDas Kürzel "-c pytorch" am Ende des letzten Befehls sagt unserem Installationsbefehl, die Pakete aus dem "pytorch" Kanal zu laden (Pytorch betreibt einen eigenen Kanal für dessen Pakete).
Wichtig ist dabei außerdem das Paket "ipykernel", das einen Python-Kernel bereitstellt und somit automatisch von unserem jupyter Environment erkannt wird.
Nach der Installation wechseln wir wieder zu unserem jupyter Environment, starten Jupyterlab und haben nun die Möglichkeit, dmml Notebooks zu erstellen.
(dmml) $> conda activate jupyter
(jupyter) $> jupyter-labIn Jupyterlab sollte nun das dmml Environment ersichtlich sein!
Bonus: Netter Nebeneffekt
Für alle unter euch, die gerne in Microsoft's Visual Studio Code [10] oder Jetbrain's PyCharm [11] entwickeln, auch hier funktioniert dieses Setup und das Tool eurer Wahl bietet euch bei Notebooks die gleiche Auswahl an installierten Environments an!
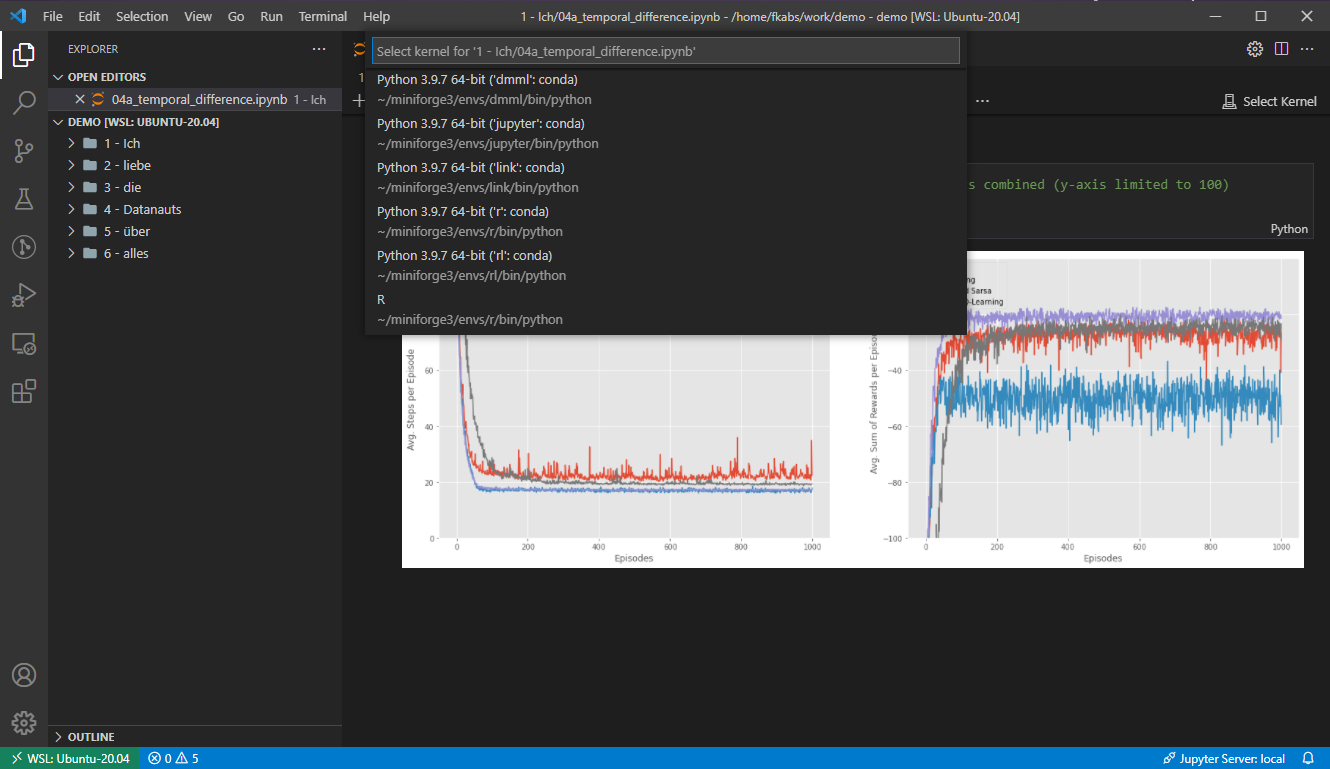
Miniforge Environments am Beispiel von Visual Studio Code
(Quelle: Privat | Fabian Kovac)
Zusammenfassung
Während sich Anaconda [1] mit den neuen Lizenzbedingungen [5] in der Community unbeliebt macht, tritt diese Community mit eigenen Lösungen immer mehr in der Vordergrund.
Miniforge [9] aus dem Hause conda-forge [7] bietet dabei die optimale und bessere Alternative, um auch in Zukunft weiterhin nachvollziehbar und transparent seinen Data Science Projekte nachgehen zu können - und wenn man die Trennung in Environments beherzigt, auch ohne sich dabei zu ärgern, eine bestehende Installation wieder in den Sand gesetzt zu haben....
Referenzen
[1] Continuum Analytics Inc., “Anaconda | The World’s Most Popular Data Science Platform,” Anaconda, Jul. 17, 2012. https://www.anaconda.com/ (accessed Oct. 02, 2021).
[2] Continuum Analytics Inc., “Miniconda — Conda minimal installer,” 2017. https://docs.conda.io/en/latest/miniconda.html (accessed Oct. 02, 2021).
[3] Continuum Analytics Inc., “Conda — Conda documentation,” 2017. https://docs.conda.io/en/latest/ (accessed Oct. 02, 2021).
[4] Conda Community, conda/conda. Conda, 2021. Accessed: Oct. 02, 2021. [Online]. Available: https://github.com/conda/conda
[5] Continuum Analytics Inc., “Anaconda | Terms of Service,” Anaconda, Sep. 30, 2020. https://www.anaconda.com/terms-of-service (accessed Oct. 02, 2021).
[6] Continuum Analytics, Inc., “Anaconda | Commercial Edition,” Anaconda. https://www.anaconda.com/products/commercial-edition (accessed Oct. 02, 2021).
[7] Conda-Forge Community, “The conda-forge Project: Community-based Software Distribution Built on the conda Package Format and Ecosystem,” Jul. 2015, doi: 10.5281/ZENODO.4774216.
[8] Intel Corporation, “Accelerate Fast Math with Intel® oneAPI Math Kernel Library,” Intel, 2021. https://www.intel.com/content/www/us/en/develop/tools/oneapi/components/onemkl.html (accessed Oct. 02, 2021).
[9] Conda-Forge Community, Miniforge. conda-forge, 2021. Accessed: Oct. 02, 2021. [Online]. Available: https://github.com/conda-forge/miniforge
[10] Microsoft Corporation, “Visual Studio Code - Code Editing. Redefined.” https://code.visualstudio.com/ (accessed Oct. 02, 2021).
[11] JetBrains s.r.o., “PyCharm: the Python IDE for Professional Developers by JetBrains,” JetBrains. https://www.jetbrains.com/pycharm/ (accessed Oct. 02, 2021).

Fabian Kovac
studiert Data Science and Business Analytics an der FH St. Pölten und ist als Student Researcher in der Forschungsgruppe Data Intelligence beschäftigt