
Erstellung eines Basis-Trainingsplans
Vor der Erstellung eines Basis-Trainingsplans sollte sich jeder\jede Athlet*in grundsätzlich einer Leistungsdiagnostik unterziehen.
Sportmedizinische Leistungsprüfverfahren haben als wesentliche Aufgaben die Überprüfung der Gesundheit und der Sport- und Belastungstauglichkeit von Athlet*innen und die Feststellung des aktuellen Leistungszustandes unter standardisierten Bedingungen als Grundlage für weiterführende sportmedizinische und trainingspraktische Entscheidungen (P. Hofmann, M. Wonisch, and R. Pokan, “Laktat-Leistungsdiagnostik: Durchführung und Interpretation” in Kompendium der Sportmedizin. Springer, 2017, p. 191.).
Für die automatisierte Erstellung eines Basis-Trainingsplans bieten sich zwei Herangehensweisen an:
Stehen keine Trainingsdaten aus den vergangenen Saisonen zur Verfügung, kann ein Plan ausschließlich auf den Daten einer Leistungsdiagnostik basieren. In diesem Fall wird eine automatisierte Planung in Form des domain-independent planning empfohlen.
Sind Vergangenheitsdaten verfügbar, kann ein neuer Trainingsplan auch anhand dieser Daten entworfen werden. Bei dieser Variante bietet sich das Konzept eines Artificial Sport Trainers (AST) an.
Domain-independent planning
Ziel der automatisierten Planung ist das Finden teilweiser oder vollständig geordneter Abfolgen von Aktionen, um von einem definierten Ausgangszustand in einen gewünschten Zielzustand zu gelangen. Um den Zielzustand so gut als möglich zu erreichen, ist eine detaillierte Beschreibung des Problems und der Umwelt (Domain) notwendig.
Beim domain-independent planning werden für jede Sportart die notwendigen Attribute und die unterschiedlichen Trainingseinheiten global innerhalb der Domainspezifikation beschrieben. Diese Spezifikation gilt somit für alle Athleten*innen, die dieselbe Art von Training durchführen. Einzelne Trainingsabschnitte werden als Aktionen definiert, die wiederum über Parameter, Vorbedingungen und die Effekte, die bei der Ausführung der Aktion geschehen, beschrieben.
Die Individualisierung erfolgt über die Problemspezifikation, die für jede Athletin / jeden Athleten angelegt werden muss. In dieser werden die Startwerte definiert. Dazu zählen die maximale Anzahl bestimmter Arten von Übungen pro Woche und die Ergebnisse der Leistungsdiagnostik (Attribute). Weiter müssen Zielwerte festgelegt werden. Dabei handelt es sich um gewünschte Mindestwerte der Attribute der Athleten, die durch die Einhaltung des Trainingsplans erreicht werden sollen.
Die Modellierung und Beschreibung der Domain- und Problem-Spezifikation erfolgt über die Planning Domain Definition Language (PDDL). Mittels der PDDL werden die Vor- und Nachbedingungen einer Aktion definiert. Das Planungsproblem wird durch die Kopplung der Domänen- mit der Problemspezifikation erzeugt.
Für die endgültige Generierung eines individuellen Trainingsplans wird ein Planer verwendet, der die Domain- und Problemspezifikation verarbeitet. Local Search for Planning Graphs (LPG) ist ein solcher Planer, der auf lokalen Such- und Planungsgraphen basiert.
Tomas Skerik untersuchte während seiner Forschungstätigkeit an der University of Huddersfield, ob mittels der automatisierten Planungsmethode Trainingspläne detaillierter und individueller gestalten werden können. Das zugrundeliegende Planungsmodell wurde auf Github zur Verfügung gestellt (SMC2018SportDomain)
Das Ergebnis der Arbeit zeigt, dass die manuelle Erstellung eines individuellen Trainingsplans mehrere Stunden in Anspruch nimmt. Mit dem automatisierten Modell hingegen konnten innerhalb weniger Sekunden individuelle, weitaus detailliertere Trainingspläne entworfen werden. Die beiden nachfolgenden Tabellen verdeutlichen diese Unterschiede:
Vergleich Trainingspläne (Quelle: T. Skerik, L. Chrpa, W. Faber, and M. Vallati, “Automated training plan generation for athletes” in 2018 IEEE International Conference on Systems, Man, and Cybernetics (SMC). IEEE, 2018, p. 3869.)
Artificial Sports Trainer (AST)
Ein Artificial Sports Trainer (AST) dient dazu, die Fülle an Daten, die während einer Trainingseinheit aufgezeichnet werden, vernünftig auszuwerten und zu interpretieren. Ein AST basiert auf Computational Intelligence (CI)-Algorithmen, die zur Wissensanreicherung auf diese gesammelten Daten zurückgreifen.
Die Hauptaufgabe eines AST besteht darin, den Trainingsprozess zu planen, zu überwachen, zu steuern, zu analysieren und Entscheidungen zu treffen. Ein AST ist in der Lage, die vorhandenen Trainingsdatensätze zu klassifizieren, zu gruppieren, zu analysieren und Data Mining durchzuführen. Auf dieser Grundlage basiert die Vorhersage zukünftiger Trainingseinheiten, die für die Leistungssteigerung am besten geeignet sind.
Die nachfolgende Abbildung beschreibt die Architektur eines AST zur Generierung einer Trainingsstrategie auf Basis bereits bestehender Trainingseinheiten.
Architektur eines Artificial Sports Trainer (Quelle: I. Fister Jr and I. Fister, “Generating the training plans based on existing sports activities using swarm intelligence” in Nature-Inspired Computing and Optimization. Springer, 2017, p. 83.)
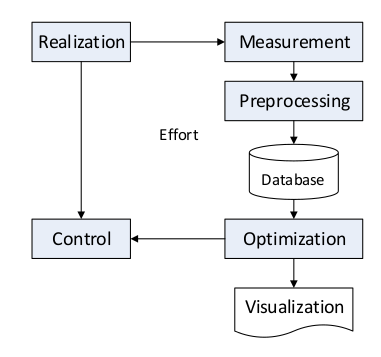
Die Realisierungsphase entspricht der Umsetzung der Trainingsvorgaben durch den Athleten / die Athletin, und wird mit Hilfe von Sports-Trackern gemessen (Messung).
Die Steuerung, die in der Vergangenheit von einem\r humanen Trainer*in durchgeführt wurde, übernimmt der Sports-Tracker.
Die Vorverarbeitung besteht aus vier Schritten:
Zusammenstellung und Identifizierung sportlicher Aktivitäten durch den Sports-Tracker bereits während der Trainingseinheit
Analyse der Trainingsdaten durch den AST
Quantifizierung der Trainingsbelastung über einen berechneten Indikator wie z.B. das TRIMP (TRaining IMPulse) Konzept.
` TRIMP = t * HR `
` t ` ___ Dauer der Trainingseinheit in Minuten (min)
` HR ` __ Durchschnittliche Herzfrequenz in Schlägen pro Minute (bpm)
Clustering der einzelnen Trainingseinheiten gemäß dem identifizierten TRIMP-Trainingslastindikator in Gruppen von Trainingseinheiten mit ähnlichen Intensitäten. Das Clustering erfolgt über k-means.
Es existieren eine Fülle von Online-Diensten und -Anwendungen, in denen die Funktionsweise eines AST integriert ist, wie z.B. Strava, Garmin Connect, TrainingPeaks. Hierfür müssen die Trainingsdaten auf die Server des jeweiligen Anbieters hochgeladen und in deren Datenbanken gespeichert werden.
Bei der Optimierung wird bereits ein Trainingsplan für die Dauer eines Trainingszyklus erstellt. Hierbei werden die einzelnen Trainingseinheiten so verteilt, dass jeweils zu Beginn und am Ende des Zyklus die moderaten Einheiten liegen, während die intensiveren in der Mitte des Zyklus zugeteilt werden. Der Optimierungsalgorithmus muss die richtigen Trainingseinheiten aus den verschiedenen Clustern in den Trainingsplan aufnehmen, damit die geforderte Intensitätsverteilung berücksichtigt wird. Diese Optimierung erfolgt über naturinspirierte Algorithmen, wie der Particel Swarm Intelligence (PSO) oder dem Bat-Algorithmus.
Die Visualisierung eines Trainings sowie eines Trainingszyklus erfolgt ebenfalls über die bereits genannten Online-Dienste und -Anwendungen.
Fazit
Künstliche Intelligenz erleichtert uns bereits heute in vielen Einsatzgebieten den Alltag erheblich.
Durch den Einsatz von domain-independent planning kann der Arbeitsaufwand für die Erstellung individueller Trainingspläne auf ein Minimum reduziert werden. Die Domänenmodellierung ermöglicht einen Detaillierungsgrad und eine Vielfalt bei der Ausgestaltung eines Trainingsplans, die auf manuellem Weg kaum möglich ist. Um individuelle Trainingspläne zu erhalten, muss jedoch für Athlet*innen einer Sportdisziplin eine eigene Problemspezifikation beschrieben werden. Sobald die Domain- und Problemspezifikation beschrieben sind, kann ein individueller, detaillierter Trainingsplan innerhalb von Sekunden automatisiert generiert werden.
Gezielte Datenerfassung mittels Sports-Trackern und die Verwendung eines AST ermöglichen die computergestützte Abwicklung des gesamten Trainingsplanungsprozesses. Im Gegensatz zuhumanen Trainer*innen kann ein AST enorme Datenmengen verarbeiten und analysieren. Ein AST ist in der Lage, präzisere, umfassendere und qualitativ hochwertigere Analysen anzubieten, als es humane Trainer*innen je könnten. Dadurch wird es Athlet*innen ermöglicht, auch ohne teure Personal-Trainer*innen ein systematisch geplantes Training durchzuführen. Selbst die Auswertung des erreichten Leistungsfortschritts kann durch einen AST kostengünstig und detailliert erfolgen.
Referenzen
T. Skerik, L. Chrpa, W. Faber, and M. Vallati, “Automated training plan generation for athletes” in 2018 IEEE International Conference on Systems, Man, and Cybernetics (SMC). IEEE, 2018, p. 3865–3870.
M. Fox and D. Long, “PDDL2. 1: An extension to PDDL for expressing temporal planning domains” Journal of artificial intelligence research, vol. 20, pp. 61–124, 2003.
A. Gerevini, A. Saetti, and I. Serina, “Planning through stochastic local search and temporal action graphs in lpg” arXiv preprint arXiv:1106.5265, 2011.
I. Fister Jr and I. Fister, “Generating the training plans based on existing sports activities using swarm intelligence” in Nature-Inspired Computing and Optimization. Springer, 2017, pp. 79–94.
I. Fister, A. Iglesias, E. Osaba, U. Mlakar, and J. Brest, “Adaptation of sport training plans by swarm intelligence” in 23rd International Conference on Soft Computing. Springer, 2017, pp. 56–67.
I. Fister, S. Rauter, X.-S. Yang, K. Ljubiˇc, and I. Fister Jr, “Planning the sports training sessions with the bat algorithm” Neurocomputing, vol. 149, pp. 993–1002, 2015.
