
Woran Data Science Projekte scheitern
Aktuell scheitern 85% aller Big Data Projekte [12] und 87% an Data Science Projekten schaffen es nie in die Produktion [15]. Bis 2022 werden schätzungsweise nur rund 20% an analytischen Erkenntnissen zu Geschäftergebnissen führen [16]. Diese Zahlen werfen eine große Frage auf: Warum scheitern Data Science Projekte?
Die "Data Science Process Alliance" hat diese Frage genauer unter die Lupe genommen und konnte die häufigsten 8 Gründe dafür finden [10] :
Falsche Daten: Der Mangel an ausreichender Menge und Qualität stellt nach wie vor eine große Herausforderung für die Entwicklung dar [11].
Mangelnde Qualifikationen der Mitarbeiter: Data Science/Analytics ist nach "Cyber Security" die am zweitschwersten zu findene Qualifikation [9].
Falsch formulierte Problemstellungen: Projekte werden oft mit unscharfen Vorstellungen und unklar definierten Zielen begonnen, die weder realistisch sind, noch einen Mehrwert bringen [10].
Kein Mehrwert: Nur rund 15% der führenden Unternehmen haben KI-Funktionen erfolgreich in Produktion eingesetzt [13].
Umsetzung als letzter Schritt: Nach der Umsetzung werden Projekte regelricht liegen gelassen und neu generierte Daten bringen keinen Mehrwert [10].
Mangelnde Ethik: Falsch angewandt kann AI zu schwerwiegenden ethischen, markenpolitischen und rechtlichen Problemen führen [5].
Mangelnde Unternehmenskultur: Führungskräfte berichten, dass kulturelle Herausforderungen oft das größte Hindernis in der Realisierung von Geschäftsergebnissen darstellen [6] und Data Science Projekte sind hier keine Ausnahme.
Falscher (kein) Prozess: Ohne ein etabliertes und klares Projektmanagement greifen Unternehmen häufig auf Ad-hoc-Projekte zurück, was zu einem ineffizientem Informationsaustausch, verpasste Gelegenheiten und falsche Analysen führen kann [10].
Doch all diese Probleme sind nichts Neues. Schon 2014 konnte die Capgemini in einer Studie feststellen, dass rund drei Viertel aller Big Data Projekte scheitern [7]. Nach David Becker sind mangelndes Projektmanagement und organisatorische Probleme die häufigsten Ursachen für das Scheitern von Big Data Projekten [1] :
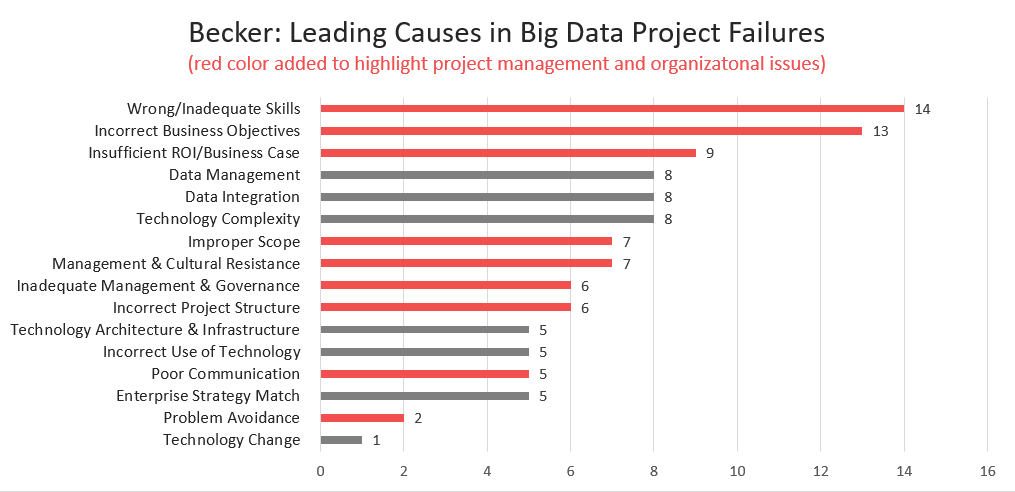
Becker: Häufige Ursachen für scheiternde Big Data Projekte [1]
(Quelle: Data Science Process Alliance, "Why Big Data Science & Data Analytics Projects Fail" [9])
Doch wie sollten man Data Science Projekte nun organisieren und in Angriff nehmen? CRISP-DM könnte die Lösung sein!
Der CRISP-DM Prozess unter der Lupe
Der Cross Industry Standard Process for Data Mining (CRISP-DM) ist ein schon 1999 vorgestelltes Prozessmodell mit 6 Phasen, das den Lebenszyklus von Data Mining Projekten auf natürliche Weise beschreibt [2] [4]. Dieses Modell kann wie eine Art Roadmap für Data Science Projekte verstanden werden, die bei der Planung, Organisation und Umsetzung helfen soll [8].
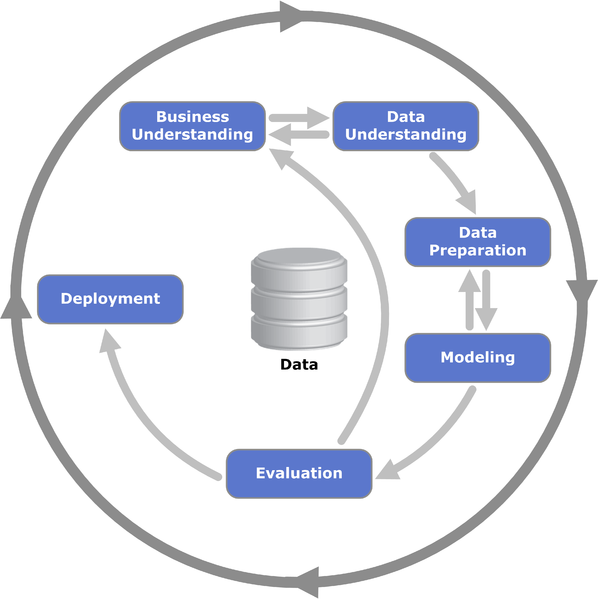
CRISP-DM Prozessmodell
(Quelle: P. Chapman et al., "CRISP-DM 1.0: Step-by-step data mining guide" [2])
Besonders hervorzuheben ist hierbei der stetige Prozess, selbst nach Beendigung eines Projektes, da sich Ziele langfristig verändern können und auch nach dem Deployment weiterhin Daten gesammelt und analysiert werden. CRISP-DM bildet dies optimal ab und bietet mit den 6 Phasen eine gute Richtlinie zur Durch- und Weiterführung von Data Science Projekten.
Die CRISP-DM Phasen
Business Understanding
Jedes erfolgreiche Projekt beginnt mit einem tiefen Verständnis für das Problem und die Bedürfnisse, die es zu lösen gibt. Data Science Projekte bilden hier keine Ausnahme und CRISP-DM hat dies in der ersten Phase abgebildet.
In dieser Phase geht es darum, die Ziele und Anforderungen zu verstehen. Hierbei handelt es sich oft um grundlegende Methoden des Projektmanagements, die ohnehin für die meisten Projekte gelten:
Zielbestimmung: Die Bestimmung der Ziele sowie deren (messbaren) Erfolgskriterien
Bewertung der Situation: Anforderungen, Verfügbarkeit von Ressourcen, Risiken und Kosten-Nutzen-Analyse
Data Mining Ziele: Definition der Ziele aus technischer Sicht
Projektplan: Detaillierte Beschreibung der einzelnen Projektphasen und dazugehöriger Arbeitspakete
Data Understanding
Das Verständnis für die Daten ergänzt die Grundlage der Business Understanding Phase und legt die Schwerpunkt auf die Identifikation, Sammlung und Analyse der Datenbestände, die für das Projekt relevant sind. Diese Phase besteht grundlegend aus vier Aufgaben:
Sammeln der Daten: Erfassung aller erforderlicher Daten sowie deren Metadaten
Datenbeschreibung: Untersuchung und Beschreibung der Daten sowie deren Eigenschaften
Untersuchung der Daten: Genauere Analysen und Visualisierung sowie Abbildung der Beziehungen zwischen den Daten
Datenqualität: Prüfung, Dokumentation und transparente Messung der Daten anhand der Datenqualitätskriterien
Data Preparation
Eine allgemein Faustregel besagt, dass 80% eines jeden Data Science Projekts auf die Aufbereitung und Vorverarbeitung der Daten entfallen. Für diese Phase sollte besonders viel Zeit und Know-How eingeplant werden, da hier der Grundstein für die Erreichung der Ziele gelegt wird.
Selektion der Daten: Festlegung und Dokumentation, welche Daten und welche Features verwendet werden
Datenbereinigung: Oft die langwierigste aber wichtigste Aufgabe, um korrekte Datenbestände zu gewährleisten
Feature Engineering: Erstellung und Bildung weiterer Attribute, die sich aus den Daten ableiten lassen
Integration: Kombination und Verschmelzung der Daten verschiedener Quellen
Formatierung: Formatierung der Daten (-Attribute) auf das benötigte Format (z.B. Spalte x beinhaltet nur Gleitkommazahlen mit zwei Nachkommastellen)
Modeling
Die spannendste und aufregendste Phase ist leider oft auch kürzeste Phase des Projekts. Hier werden verschiedene Modelle auf der Grundlage unterschiedlicher Modellierungsverfahren erstellt, trainiert und bewertet.
Auswahl der Verfahren: Bestimmung der Algorithmen, die zum Einsatz kommen (Regression, neuronales Netz, etc.)
Testentwurf: Abhängig vom Verfahren sollten die Daten normalisiert, Dimensionen reduziert und in Trainings-, Validierungs- und Testdaten aufgeteilt werden
Modellerstellung: Erstellung und Training des Modells (Regression, Klassifikation, etc.)
Bewertung: Bewertung und Interpretation der Modellergebnisse auf Grundlage vordefinierter Erfolgskriterien
In dieser Phase ist es besonders wichtig, transparente, interpretierbare und nachvollziehbare Ergebnisse zu erzielen. Diese Phase kann über sog. Modelliterationen so lange wiederholt werden, bis gute Ergebnisse erzielt werden.
Die besten Modelle sind oft nicht die perfektesten Lösungen, aber gut genug, einfach und leicht zu interpretieren und zu warten. Don't let perfect be the enemy of great!
Evaluation
Während die Bewertung des Modells aus technischer Sicht in der Modeling Phase durchgeführt wird, konzentriert sich die Evaluation Phase darauf, welches Modell sich am besten für das Unternehmen bzw. das Ziel eignet und wie die nächsten Schritte definiert werden.
Bewertung der Ergebnisse: Bewertung der Modelle nach Erfüllung der Erfolgskriterien aus der Business Understanding Phase
Überprüfung der Prozesse: Zusammenfassung der Ergebnisse sowie Korrektur der Modeling Phase, wenn etwas nicht ordnungsgemäß ausgeführt wurde
Bestimmung der nächsten Schritte: Festlegung auf der Grundlage der Data Understanding, Data Preparation und Modeling Phase, ob mit Implementierung fortgefahren wird, oder weitere Iterationen vorgenommen werden
Deployment
Je nach Anforderungen kann die Phase der Implementierung völlig unterschiedlich sein. Sie kann so einfach wie die Erstellung eines Berichts in einem Analytics-Projekt sein oder so komplex wie die weltweite Ausrollung des Data Mining Prozesses in einem internationalen Unternehmen. In Forschungs- und Entwicklungsprojekten bildet die Deployment Phase oft die Disseminationsphase ab, wobei ein Disseminationsplan erstellt und die Ergebnisse publiziert werden.
Implementierung: Entwicklung und Dokumentation des Plans für die Implementierung
Überwachung und Wartung: Nachprojektphase, Entwicklung und Dokumentation eines Überwachungs- und Wartungsplans, um Probleme in der Betriebsphase zur erkennen und zu vermeiden
Abschlussbericht: Dokumentation und Zusammenfassung des Projekts sowie abschließende Präsentation der Ergebnisse
Rückblick: Überprüfung der CRISP-DM Durchführung sowie Rückblick, was gut gelaufen ist und was in Zukunft verbessert werden kann
Nach der Deployment Phase ist das Projekt aber meist nicht beendet und abgehakt. CRISP-DM beschreibt auch nicht explizit, was nach einem Projekt zu tun ist. Wenn ein Modell jedoch in Produktion geht, sollte auch sichergestellt werden, dass es auch in Produktion gehalten wird. Eine ständige Überwachung und gelegentliche Anpassung ist oft erforderlich, da selbst nach Implementation weitere Daten generiert werden und sich Ziele oft verändern.
Es gibt viele Methoden und Prozesse zur Planung und Organisation von Data Science Projekten, CRISP-DM ist dabei aber das am beliebtesten und erfolgreichsten eingesetzte Modell [14]. Selbst in aktuelle Entwicklungen mit Hinblick der Prozessgestaltung bildet CRISP-DM immer noch die Basis, wie zum Beispiel bei sog. "Data Science Trajectories" [3], die immer noch den Originalprozess beibehalten, aber einzelne Phasen genauer und je nach Anwendungsfall steuern.
CRISP-DM bildet mit den sechs Phasen den De-Facto-Standard zur Planung von Data Science Projekten und trägt richtig eingesetzt, maßgeblich zur Umsetzung erfolgreicher Projekt bei.
Referenzen
[1] D. K. Becker, “Predicting outcomes for big data projects: Big Data Project Dynamics (BDPD): Research in progress,” in 2017 IEEE International Conference on Big Data (Big Data), Dec. 2017, pp. 2320–2330. doi: 10.1109/BigData.2017.8258186.
[2] P. Chapman et al., “CRISP-DM 1.0: Step-by-step data mining guide,” 1999.
[3] F. Martínez-Plumed et al., “CRISP-DM twenty years later: From data mining processes to data science trajectories,” IEEE Trans. Knowl. Data Eng., vol. 33, no. 8, pp. 3048–3061, 2021, doi: 10.1109/TKDE.2019.2962680.
[4] R. Wirth and J. Hipp, “Crisp-dm: towards a standard process modell for data mining,” 2000.
[5] R. Benjamin, “Assessing risk, automating racism,” Science, vol. 366, no. 6464, pp. 421–422, 2019, doi: 10.1126/science.aaz3873.
[6] businesswire, “NewVantage Partners Releases 2021 Big Data and AI Executive Survey,” Jan. 04, 2021. https://www.businesswire.com/news/home/20210104005022/en/NewVantage-Partners-Releases-2021-Big-Data-and-AI-Executive-Survey (accessed Nov. 28, 2021).
[7] Capgemini Consulting, “Cracking the Data Conundrum: How Successful Companies Make Big Data Operational,” Jan. 2015. Accessed: Nov. 28, 2021. [Online]. Available: https://www.capgemini.com/gb-en/resources/cracking-the-data-conundrum-how-successful-companies-make-big-data-operational/
[8] Data Science Process Alliance, “CRISP-DM,” Data Science Process Alliance, Aug. 24, 2021. https://www.datascience-pm.com/crisp-dm-2/ (accessed Nov. 28, 2021).
[9] J. DuBois, “The Data Scientist Shortage in 2020,” QuantHub, Apr. 07, 2020. https://quanthub.com/data-scientist-shortage-2020/ (accessed Nov. 28, 2021).
[10] N. Hotz, “Why Big Data Science & Data Analytics Projects Fail,” Data Science Process Alliance, Feb. 13, 2021. https://www.datascience-pm.com/project-failures/ (accessed Nov. 28, 2021).
[11] IDC, “IDC Survey Finds Artificial Intelligence Adoption Being Driven by Improved Customer Experience, Greater Employee Efficiency, and Accelerated Innovation,” IDC: The premier global market intelligence company, Jun. 10, 2020. https://www.idc.com/getdoc.jsp?containerId=prUS46534820 (accessed Nov. 28, 2021).
[12] B. T. O’Neill, “Failure rates for analytics, AI, and big data projects = 85% – yikes! | Designing for Analytics (Brian T. O’Neill),” Jul. 23, 2019. https://designingforanalytics.com/resources/failure-rates-for-analytics-bi-iot-and-big-data-projects-85-yikes/ (accessed Nov. 28, 2021).
[13] G. Press, “AI Stats News: Only 14.6% Of Firms Have Deployed AI Capabilities In Production,” Forbes, Jan. 13, 2020. https://www.forbes.com/sites/gilpress/2020/01/13/ai-stats-news-only-146-of-firms-have-deployed-ai-capabilities-in-production/ (accessed Nov. 28, 2021).
[14] J. Saltz, “CRISP-DM is Still the Most Popular Framework for Executing Data Science Projects,” Data Science Process Alliance, Nov. 30, 2020. https://www.datascience-pm.com/crisp-dm-still-most-popular/ (accessed Nov. 28, 2021).
[15] VentureBeat, “Why do 87% of data science projects never make it into production?,” VentureBeat, Jul. 19, 2019. https://venturebeat.com/2019/07/19/why-do-87-of-data-science-projects-never-make-it-into-production/ (accessed Nov. 28, 2021).
[16] A. White, “Our Top Data and Analytics Predicts for 2019,” Andrew White, Jan. 03, 2019. https://blogs.gartner.com/andrew_white/2019/01/03/our-top-data-and-analytics-predicts-for-2019/ (accessed Nov. 28, 2021).

Fabian Kovac
studiert Data Science and Business Analytics an der FH St. Pölten und ist als Student Researcher in der Forschungsgruppe Data Intelligence beschäftigt